The Wikimedia Hackathon took place in Prague six weeks ago. My main project there was inteGraality, a self-service dashboard of property coverage for any given part of Wikidata. Here is a short recap of how it came to be.
How it all started
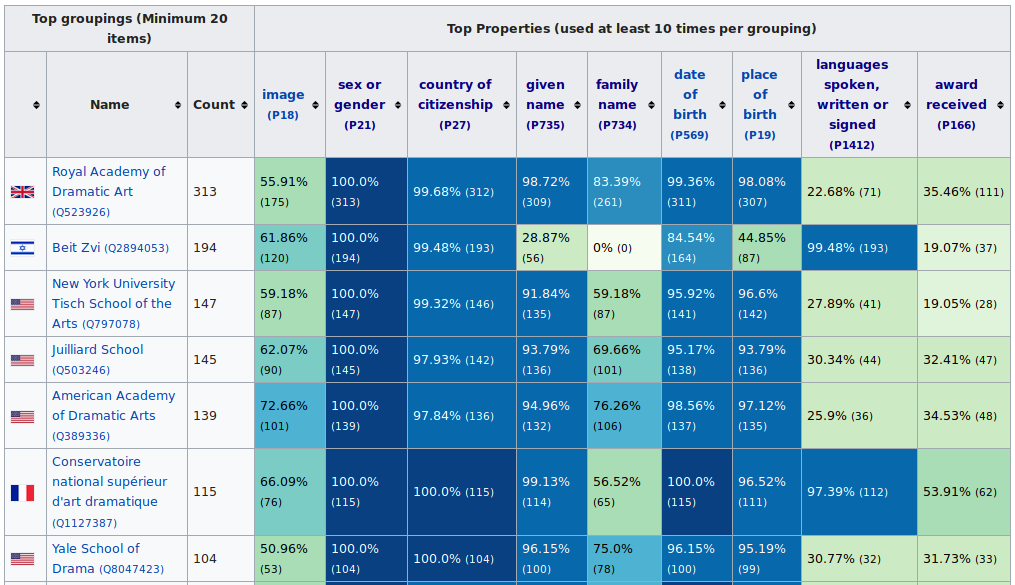
It all started, as often, with the Sum of all Paintings. This Wikidata WikiProject aims “to get an item for every notable painting”, and is a quite mature and advanced Wikidata project − I for one often turn to it for ideas to apply to other projects (like my baby Sum of all Videogames).
So when last April, Maarten and Liam announced a Property statistics dashboard, allowing to “track the completion % of the most commonly used properties for paintings, on a per-collection basis”, I did not take long to adapt the concept and the code (helpfully open-sourced by Maarten) to the VG project: the “collections” became “platforms”, but besides that it was pretty much the same thing. It turned out I was not the only one inspired: User:Bodhisattwa also made a similar dashboard for railways.
This positive reaction prompted Maarten to file the following requirements on Phabricator:
Let’s build a service to offer these kind of statistics.
– Service is Pywikibot based and runs under a tools account on Toolforge
– Every page in need of statistics has a start and end template just like Listeriabot
– The start template contains all the relevant variables for the bot to function
– The bot runs every once in a while to update these pages (might implement manual run too)
As I was looking for a project to tackle at the upcoming Prague hackathon, that sounded like a plan 🙂
Hackathon
Scope
The requirements (as defined by Maarten) were clear, and I set to myself a simple acceptance criteria: the tool must be able to recreate both the paintings and the video games dashboards. Both dashboards had actually already diverged:
- the paintings one had a column for the country of the collection, which I had ditched for video games. I was tempted to move that feature to nice-to-have, but Maarten convinced me this feature should be kept.
- the video games one had support for linking to report sub-pages.
I also had one additional feature, which had been suggested by @Nicereddy: display the statistics for items which do not have a collection. This felt small enough and useful enough to squeeze in a first release.
Definitions and naming
The existing code was using domain-specific vocabulary for naming of variables and methods (`?painting` and `?game`, `getCollection`…). Picking good names helps finding the right abstractions, and can save a lot of headache later.
I actually thought that “collection” was a fine name, as not necessarily tied to “art gallery collection” − but we nevertheless came up with the more abstract “grouping”. The “country of collection” feature was thus rebranded “higher-grouping”. And the bit of SPARQL used to select the items you are interested in (eg, paintings or videogames) was dubbed “selector_sparql”.
Inputs
Now equipped with good definitions, I could define the inputs for the service. I worked on the code (mashing up from both the paintings and the games one) to make it domain-agnostic − extracting the hardcoded domain-specific parts and moving them to class attributes, passed as arguments from the outside.
As the tool ultimately boils down to SPARQL queries, we had to make a decision on the simplicity/power trade-off. For the “grouping”, should we only ask for a property number and then construct the full SPARQL query from it; or should we ask for a SPARQL fragment (which has to use some predefined variable name), which is more complex but allows for more powerful groupings? I decided to go for the former, as my priority was more to make the tool accessible to non-SPARQL wizards.
Around mid-day, I created the first-version of {{Property dashboard}}, with the class inputs defined above as parameters.
Code, debug, repeat
My recollections of the rest of the afternoon are a bit blurry: lots of coding, debugging, interfacing with Pywikibot and wikitext-wrangling (and testing out).
I was initially iterating on a PAWS Jupyter notebook, so that I conveniently would not have to care at that point about authentication or the pywikibot dependency. It quickly became frustrating though, as I needed to frequently copy/paste between my local editor and the notebook, and I could hardly write unit-tests. At some point I moved the development locally.

(Pebaryan, CC-By-SA)
Naming, again
Midnight was closing in, the code was mostly there and it was about time to store it all under Git (arguably, should have been done much earlier). One last piece was missing though: how to name this project? I approached TheDJ − coding at the other end of the room − and we bounced naming ideas, puns and plays on the concepts of coverage and completion. The short-listed was user-tested on a couple of folks, and I settled on `inteGraality`.
The following components could now be created:
- Git repository, on Github;
- bot account, aptly named “InteGraalityBot”;
- tool account on the Wikimedia Toolforge.
The Git repo came with the classic scaffolding: infrastructure for linting, unit tests, dependency management.
Deployment
Now, time to deploy the code onto Toolforge. I had been relying for a while now on some simple Ansible playbooks for configuration management and deployment On Toolforge (abusing somewhat the SSH+become access workflow). However, ever since the migration to Debian Stretch, this was not working anymore. I ambushed Bryan, the Toolforge man himself, and we figured out a workaround. With one Ansible command I could update the tool − just like it should be 🙂
Alas! In my eagerness to use the latest f-strings, I had overlooked the fact this is a Python 3.6 feature, and Toolforge only supports (for now) Python 3.5. Not the nicest discovery at 2AM, but thanks to RandomStackOverflowPost™ I had a quick drop-in replacement.
Some more tweaks later, this was all mostly working. It’s now 3.30AM − time to get some sleep.
On-demand update
Coding resumed the next day. We now had a working tool, but no way to invoke it (beside from the Toolforge shell). Time to borrow the other component from Listeria: the manual run, invoked from the wiki page.
I added a little Flask webserver, with an `update` endpoint triggering the update, and linked it from the configuration template (and for good measure, threw in a docker-compose setup to ease local development). I was worried that synchronous updates would never work, timing out before processing could end. Surprisingly enough, that worked out, and as far as I know still does. Good − I was not exactly looking forward to adding some asynchronous job queue system.
Documentation & landing page
With all that in place, I spent significant time on documentation: basic explanations on the template parameters, and turning the tool index page into something as self-explanatory as possible. Time to showcase!
Showcase
That’s the high point of the Wikimedia hackathon: 30s to show off your new awesome tool in front a (hopefully) amazed crowd!
Reactions & aftermath
The tool got positive reception. Waldir contacted me later on Telegram, suggesting a new color scheme which offers perceptual linear progression in both hue and luminance, and is color-blind-friendly.

Some crash reports came in from early adopters via Telegram − not surprising as there was virtually no error-handling. I also promoted the tool on some social media channels (Twitter and Wikidata Facebook group), where I got more error reports and questions.
Over the next two days, I added some much-needed error-handling, polished the documentation and tackled some of the bugs reported.
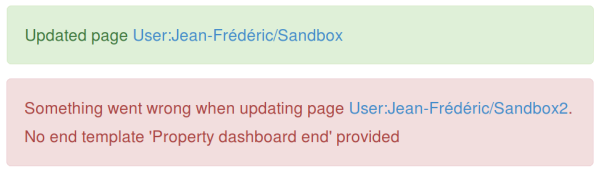
Not much, but that can be the difference between a happy user and a confused one
Lessons learnt
What went well
- Scoping
- The project was perfectly scoped for a one-person two-days hackathon. It filled up most of my time, but I got where we had planned. This is also thanks to…
- …good product management
- which sort-of became Maarten’s role (on top of his own hacking of course). Making the decisions on where to take the product and what red lines to draw scope-wise is sometimes the hardest. This saved me heaps of time, in the couple of instances where I was unsure how to proceed. I wonder if this should be part of the hackathon setup − every hacker being the “owner” or “client” of the another’s project. Of course, this ties into the bigger topic of…
- …collaboration
- It’s so useful to be able to reach out to folks, whether it’s to rubber-duck some esoteric issue or brainstorm naming. This can take other forms, such as…
- …reusing blocks
- In such a short time, being able to reuse any possible building block is very welcome. It’s hard to overstate how nice it is to be able to rely on Pywikibot for so much. Sure, it has its quirks, but it’s so liberating not having to worry about things like authentication or rate-limiting. I also could draw from Magnus’ Listeria (not so much about the code, but extensively from the overall concept to the template formatting)
- End-result quality
- I tend to be a perfectionist, and I’m fairly happy with the result as a hackathon project: dependency management, tests, local development environment… I’m confident I’ll be fine coming back that project every once in a while, and I like to think that an interested developer could easily start hacking on it.
What went less well
- Lack of error-handling
- I think it’s somewhat reasonable in the context of a hackathon, but some basic error-handling would have saved a couple of first-users some not so nice “502 bad gateway” − which in turn would have saved me the bug report. Which brings me to…
- The role of social media
- Getting actionable bug reports from users is always a challenge, but I felt social media particularly ill-suited for the task. Sharing the tool on Twitter and on the Wikidata-related Facebook groups was great to get the word out there, but I ended-up spending significant time and energy doing customer-service on these platforms, having to systematically ask for clarifications on questions and the underlying use-cases, and put it together as Phabricator tasks myself. Which is really not the most pleasant thing to do, nor necessarily the best use of my time.
Conclusion
Six weeks after the hackathon, and there are 81 dashboards powered by inteGraality (albeit not all very functional).
The topics covered range from Dutch academics to British MPs, from camera models to lighthouses, from board games by publisher to theatre actors by school, from red pandas to cartridges, and even the Wikidata properties themselves.
All in all, InteGraalityBot has performed over 400 updates,which is not too shabby considering that the automatic weekly updates have never-ever worked ^_^ (I ought to fix that at some point). EDIT: now fixed \o/
It’s likely that much of it is from the initial enthusiasm. It’s also fair to say that inteGraality is still missing some critical features, particularly to make the reports actionable, which goes in the way of wider adoption. Nevertheless, I believe the tool does answer a need from users. Just this week an inteGraality screenshot was featured in a GLAM-oriented blog-post.
I hope I’ll have time to pick up some of the items on the roadmap in the next few weeks. Of course, feel free to pitch in, whether it’s for coding or for prioritising the tasks.
It’s worth underlying that there is nothing particularly complex or clever in inteGraality code itself − as pointed out above, it’s mostly putting together existing blocks (as often is the case in software development). What makes it good is a strong product vision.
On a more general note, this reminded me of how great hackathons can be. I have no doubt my hours there were way more effective than a few dedicated evenings would have been. It’s not only about providing Wi-Fi, some quality food and an unlimited tea supply (although that sure does not hurt); it’s about creating an atmosphere suited to get work done − and on that account, the 2019 Prague Hackathon ranks among the best I’ve been to.
Credits roll
- original idea by Liam Wyatt and Maarten Dammers
- prototype by Maarten Dammers
- specifications by Maarten Dammers
- graphic design by Waldir Pimenta
- development by yours truly
- Special thanks to:
- The organizing team of the hackathon, for obvious reasons 🙂
- Magnus Manske, for Listeria from which inteGraality borrows key concepts and workflows
- TheDJ, for the late-night name-brainstorming
- Phaebz, for the occasional rubber-ducking
- Jura1, for the documentation improvements

(Pierre-Selim Huard, CC-By)

[…] to visualisation or property constraints, can be used. A tool initially conceived for paintings can be adapted to work on video […]
[…] a look on how well these items are described (a task made more straightforward this year thanks to my very own inteGraality ^_^): 5.7K have no platform (P400), 8.6K no publication date (P577), 11.3K no genre (P136) − much […]
[…] think hackathons are amazing − as I wrote before, they are great at creating an atmosphere suited to get work […]