The workshop “Videogame and Visual Media Data – Community-driven Initiatives and Research Avenues” took place at Leipzig University 3 months ago, co-organized by the diggr (Databased Infrastructure for Global Games Culture Research) and JVMG (Japanese Visual Media Graph) research projects.
I was invited to participate as a Wikidata volunteer, involved in its video game project. Here is an amended, extended, prose version of the contents of my opening statement then called “My message to video game databases: We(kidata) come in peace”.
If you are not interested in the basics of Wikidata, or not through the prism of video games, feel free to skip ahead to the more generic part.
What is Wikidata?
As [[Wikidata:Introduction]] elegantly puts it:
Wikidata is a free, collaborative, multilingual, secondary database, collecting structured data to provide support for Wikipedia, Wikimedia Commons, the other wikis of the Wikimedia movement, and to anyone in the world.
It’s worth unpacking that statement, which [[Wikidata:Introduction]] does very well again:
- Free. The data in Wikidata is published under the Creative Commons Public Domain Dedication 1.0, allowing the reuse of the data in many different scenarios. You can copy, modify, distribute and perform the data, even for commercial purposes, without asking for permission.
- Collaborative. Data is entered and maintained by Wikidata editors, who decide on the rules of content creation and management. Automated bots also enter data into Wikidata.
- Multilingual. Editing, consuming, browsing, and reusing the data is fully multilingual. Data entered in any language is immediately available in all other languages. Editing in any language is possible and encouraged.
- A secondary database. Wikidata records not just statements, but also their sources, and connections to other databases. This reflects the diversity of knowledge available and supports the notion of verifiability.
- Collecting structured data. Imposing a high degree of structured organization allows for easy reuse of data by Wikimedia projects and third parties, and enables computers to process and “understand” it.
- Support for Wikimedia wikis. Wikidata assists Wikipedia with more easily maintainable information boxes and links to other languages, thus reducing editing workload while improving quality. Updates in one language are made available to all other languages.
- Anyone in the world. Anyone can use Wikidata for any number of different ways by using its application programming interface.
Naturally, “Anyone in the world” includes (but is not limited to) researchers, database maintainers and data modelers 🙂
As for some numbers: at time of writing this, Wikidata contains over 60 million items, and clocks-in over 20,000 active editors per month. It supports labeling in over 300 languages, and it passed 1 billion edits made since its inception in 2012.
To give an impression of how active Wikidata is, you may stare at the wikistream of live edits, or listen to them.
What does it look like?
Let’s take as an example the first Star Fox game published in 1993, aka Q1326889.
As we mentioned above, Wikidata is multilingual: you’re likely getting the interface in English, but feel free to change it to German or Japanese.
Structure
Let’s break down some of the components of a Wikidata item page:

The terms used here are helpfully defined at [[Wikidata:Introduction]].
Wikidata has items, uniquely identified by a Q followed by a number, such as Q1326889. Each item has a label, a description and any number of aliases − these are particularly helpful for searching:
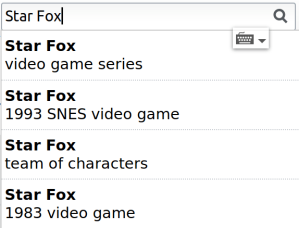

Statements and properties
Statements describe detailed characteristics of an item and consist of a property and (at least one) value. Properties in Wikidata have a P followed by a number, such as with publisher (P123). There are, at time of writing, 6723 properties (which is 418 more properties than on the workshop day). The creation of a new property follows a community process, that anyone may initiate.
Each property has a data-type − for example, publication date (P577) is of the time type. More-often than not, properties have the item data-type, and take another Wikidata item as value. For example, the value of publisher above is another item, Q8093 (Nintendo), which itself has statements. Wikidata items are therefore interconnected.

One of the most basic property used on many items is instance of (P31), in our case Q7889 (video game). Most video game items on Wikidata will be Q7889.
The other basic property is subclass of (P279) which “is used to state that all the instances of one class are instances of another”. Let’s take a closer look at the genre value: rail shooter (Q2127647) is defined as subclass of shoot ’em up (Q1044478), itself sub-class of shooter game (Q4282636) and so. Here is the trimmed graph of the parent and sibling genres of rail shooter.
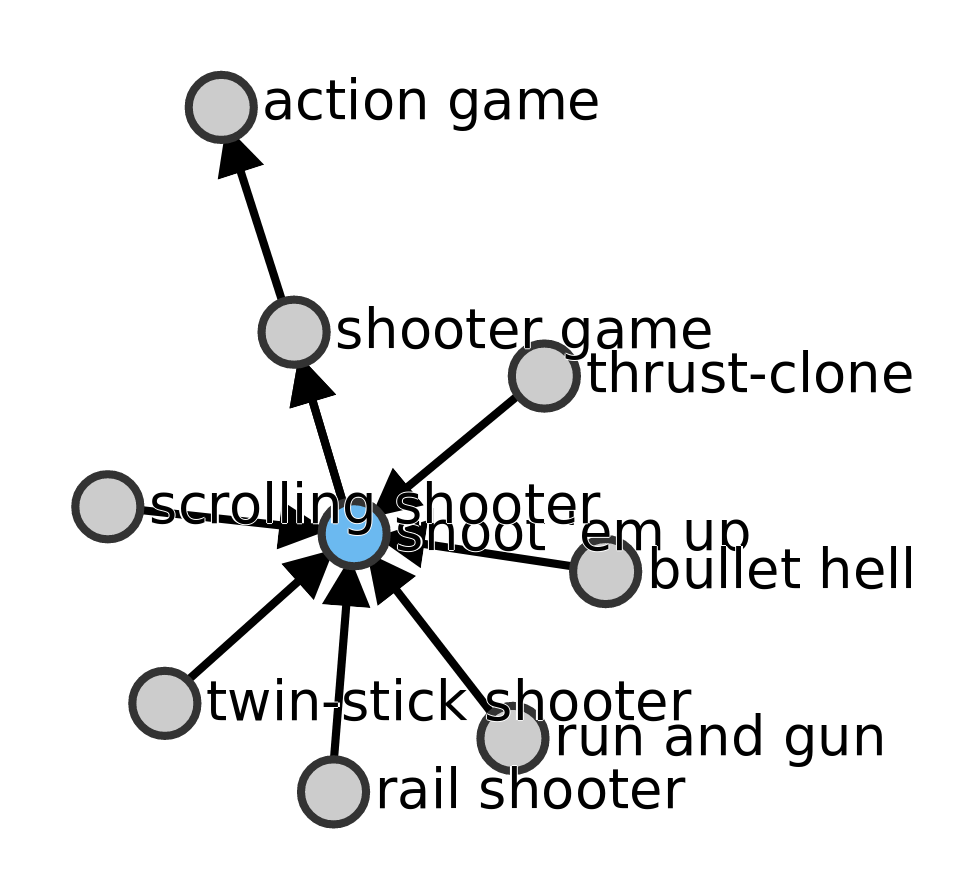
Thus, when we state that Star Fox is of the rail shooter genre, we also state transitively that it is of the shoot ’em up genre, and of the shooter genre, and so on. Later on, when we will query Wikidata for, eg, all of the shoot ’em ups published on Super Nintendo, Star Fox will pop up.
Qualifiers allow statements to be expanded on, annotated, or contextualized, and also consist of a property and a value. For example, Star Fox was published on 23 February 1993 in Japan (and only later in Europe and North-America) − we thus qualify the publication date (P577) with place of publication (P291): Japan (Q17).
Finally, references allow to indicate where the data comes from and add sources.
External identifiers
As Sandra once poetically put it: at the bottom of every Wikidata item, there is a pot of gold − external identifiers.

External identifiers are a special kind of property where the string value represents an identifier used in an external system. They are displayed as external link if a formatter URL is defined.
Out of the 6722 properties, 4340 are external identifiers. They cover topics from vaccines to file formats, from Japanese baseball players to Australian poets, from genes to roller coasters. Closer to our interests, 29 properties are related to anime and manga, and over 100 are related to video games (a situation I may have somewhat contributed to).
Creating new properties is a community-process: for example, here was the property proposal for identifiers in the Anime Characters Database.
The value of external identifiers
It is a topic I touched upon 9 months ago in my 2018 recap: cross-linking video games with external databases is my main current goal, for several reasons.
But let me say first what is not the goal:

(All rights reserved, Namco)
I don’t know if this concern is grounded in any reality, but I always worry that Wikidata may have that bad reputation: that it just aims to grow and grow, by sucking in all the data in the world − in the same way that Wikipedia once had a similar bad rap of aiming to be the alpha and omega of the web.
That is not the case, and could not be for several reasons. Some content will not be hosted on Wikidata, either because we legally can’t (eg copyrighted game covers) or because it’s somewhat outside of our scope (eg average completion time of a game). But even when we could − should we? Is there any point in duplicating data lovingly curated in a specialized database elsewhere? And were we to duplicate it, would we even have the resources (ie: the community) to maintain that data going forward? Because the value of these community-driven databases lies less in the data it holds than in the community that curates it.
No, no: as Envel elegantly put it to me, Wikidata is not the database to rule them all, but the database to link them all.
I have read this linkage described before as “the universal glue of the Internet” or as “the Internet duct tape”.

(Babi Hijau, public domain)

(Evan-Amos, public domain)
What then? A side-note on forests and fungi.
As I was thinking about it, I was somehow reminded of a Radiolab episode from three years ago: From Tree to Shining Tree (Q65109665).
From it, I learnt about how, in a forest, trees communicate with each other through mycorrhizal networks (Q16267464). These networks are created by fungi: in a symbiotic relationship with the trees, the fungus attaches itself to the roots, and creates this underground network, enabling the exchange of nutrients and information between trees − even of different species. In a cute analogy, this has been nicknamed the Wood Wide Web.

(Malene Thyssen, CC BY SA 3.0)
I believe Wikidata can be the underground fungus in the vast forest that is the Internet. With every identifier we cross-link, we are weaving this underground network, and in time we will allow these databases, even of different “species”, to talk to each other and exchange information and data. A true ecosystem.
This is not some pipe dream: it’s already happening. In his fascinating post Welcome Japan Search to the web of Linked Open Data, Martin Poulter described how he connected Wikidata to the National Diet Library’s Japan Search, enabling federated SPARQL queries − aka genie chat − across both databases.
There’s a deadline
In the forest ecosystem, when a tree is dying, it sends its remaining nutrients to the neighboring trees through the fungi network.
What happens when databases die?
On Wikipedia, there is this saying “There is no deadline”: we have time, there’s no rush to create or to delete that article.
But we also have the opposite saying: There is a deadline. Whole swaths of knowledge disappear, all the time, whether through fire, wars or natural disasters. This is a battle against time.
I’m not a librarian or an archivist, neither be training nor trade, and I can’t say I really know all that “preservation” entails. But I do feel strongly about it, and this has been a major force behind my continued dedication to Wiki Loves Monuments: documenting built cultural heritage before it’s lost, damaged or destroyed.

(Олег Сыромятников, CC BY SA 3.0)
Websites, including community-led databases, disappear all the time, leaving only behind the smoke of a “PHP version not supported”, “502 bad gateway” or “this domain is for sale”.
I may be both naive and pessimistic with that statement, but I’ll put my trust in two things: Wikimedia projects and the Internet Archive. Databases out there may have been saved in the Wayback machine, or maybe not. Either way, I want every one of them linked to Wikidata during its lifespan.
And maybe when the time comes, Wikidata can help it transfer its lifeblood to another tree, as farewell gift.
The state of video game data on Wikidata
And with this, let’s go back to some practical considerations. 🙂
The good
At time of writing, there are some 38K video game (Q7889) items on Wikidata. Many of these items are linked to Wikipedia articles in various languages, but some 3,380 are not. Looking at items linked to only one language, the most is English (as one would expect) with 6K, but then it’s to Japanese (with ~4K): while this makes sense given how many games come from Japan, it is nice to see we are not as western-centric as one might have feared.
We have all the rest of Wikidata to build upon. Do you want to indicate the narrative location (P840) of Watch Dogs (Q1371726) (Chicago (Q1297)), Lunar Lander (Q2590391) (Moon (Q405)), 1943: The Battle of Midway (Q55535) (Midway Atoll (Q47863))? Or interested in set in period (P2408) for Mercenary Force (Q57748509) (Edo period (Q184963)) or Assassin’s Creed Syndicate (Q18602166) (Victorian era (Q182688))? All 60 million items are ripe for the linking.
Wikidata offers a highly-flexible data-model: that does mean you can make statements that don’t make sense (for example, that the bowling style (P2545) of The Starry Night (Q45585) is guacamole (Q207968)) but as Denny explains in his 2013 blog post Restricting the World, this enables us to model the world in all its complexity without being bogged-down by a badly thought-of data model. In a small way, this flexibility has allowed us to use platform (P400) or distribution format (P437) in creative ways ; or to use sport (P641) on sports video games, even though that property was not initially meant for games.
Wikidata comes with batteries included. All the tools that have been made, from mass-editing to visualisation or property constraints, can be used. A tool initially conceived for paintings can be adapted to work on video games.
The bad
While 38K video game (Q7889) items are a good start, it’s still very low. At least 100,000 video games have ever been made, based on the records of MobyGames (Q612975) and IGDB (Q20056333).
The items we have are quite not complete, even for the very basic properties: half of them have no developer (P178), publisher (P123) or game mode (P404) ; one third have no genre (P136), and a quarter have no publication date (P577). Some 9K bear no external identifiers whatsoever (and 9.7K no videogame-related identifiers).
These are just the basic properties: we still have limited vocabulary (ie, properties) to describe games. To quote myself back in January:
We are missing essential vocabulary to describe things:
- to describe relationships between games. While the paper Relationships among video games: Existing standards and new definitions (Q50180192) outlines 10 other relationship types (isPortOf, isRemakeOf, isRebootOf, isPrequelOf, isExpansionOf, isSidestoryOf, isSpinoffOf, isCrossoverOf, isSpiritualSuccessorOf, isInspiredBy), Wikidata more or less boils down to based on (P144). While we may not need additional properties, we do need a better system.
- to describe game features. We do have, game mode (P404), genre (P136) and some others inherited from different media (narrative location (P840), takes place in fictional universe (P1434), set in period (P2408)). Meanwhile, the Video Game Metadata Schema also describes games in terms of mechanics, mood, narrative genre, setting, theme, trope and visual style ; IGDB has theme and player perspective ; MobyGames has visual and perspective…
As a small update: we are better equipped than what I wrote in January, as we actually do have inspired by (P941) and series spin-off (P2512), and we have devised ways of modeling remakes.
More critically, the current overarching data-model is very basic: we have Q7889 items and that’s about it − all different information on platform versions and releases are somehow compressed into one data item. This was sort of inherited from Wikipedia, where one article may compile knowledge on various elements. This has served us fine until now, but it’s showing its limits: publication dates in the 2010s pop up in queries for SNES games (because of some later iOS port) ; qualifiers are over-used on statements relevant to one platform version… We will soon need to implement a more sophisticated data model.
The work-in-progress ontology also means that we may end up with competing data models: for example, there are currently two distinct ways of modeling video game remakes:
- Worms: Ultimate Mayhem (Q2527560) instance of (P31) video game remake (Q4393107) / of (P642) Worms 3D (Q949730)
- Tomb Raider: Anniversary (Q580667) based on (P144) Tomb Raider (Q317620) / subject has role (P2868) video game remake (Q4393107)
But I think that this work-in-progress aspect is more beautiful than ugly: sure, we make things up as we go along, but it will work out in the end 🙂 Our current modeling for games is not there yet, but it’s been steadily improving.
And before we leave: some kick-ass queries
Wikidata really shines when you harness the power of the Wikidata Query Service to ask questions to Wikidata, using the SPARQL standard language. Here are some example of videogame-related questions (of course, the answers are going to be as good as the data we currently have):
- Series with the most games
- Characters from the Mario franchise by games in which they appear
(through which I learned that Dr. Mario (Q19819839) (occupation (P106): physician (Q39631)) is said to be the same as (P460) Mario (Q12379) (occupation (P106): plumber (Q252924)) − makes perfect sense)
- Video game characters named after humans
- Graph of video games genres (with OLAC vocabulary outlined)
- Timeline of games per platform
- And just because I can™: Video games whose composer is Japanese but not born in Tokyo, and less than 25 years old at the time of release
Some final words…
…to database maintainers:
- Wikidata is an opportunity and not a threat. Cross-linking with us can bring Good Things™
- Do provide persistent identifiers (preferably to a slug which may change after renaming), with a way to resolve it to a URL.
…to academics and data-modelers:
- Wikidata and Wikibase can be useful to you. If you are building a database, consider early on to link to Wikidata, and you can also consider using Wikibase as the underlying software.
- Wikidata needs you. Please bring your expertise and help sorting out a data-model.
…to anyone reading this:
- Join us! Here are some ideas on where to get started.
 This work is licensed under a Creative Commons Attribution 4.0 International License.
This work is licensed under a Creative Commons Attribution 4.0 International License.

Great article on video game data structures and benefits. I’ve posted a discussion topic about DLC’s and game expansions here for further comments and input: https://www.wikidata.org/wiki/Wikidata_talk:WikiProject_Video_games/Properties#DLC%27s_and_relationship_with_%22series_spin-off%22_and_%22plot_expanded_in%22
[…] Video games” motto. If you are not familiar with that endeavor, I extensively described it in a mushroom-rambling blog-post a few months […]
[…] A solution is to rely on other knowledge bases, Wikidata being a hub between them. In brief, as I already stated, Wikidata is not the database to rule them all, but the database to link them […]
[…] WikiProject Video games. If you are not familiar with that endeavor, I will refer you to the mushroom-rambling blog-post I wrote in September […]
[…] WikiProject Video games. If you are not familiar with that endeavor, I will refer you to the mushroom-rambling blog-post I wrote in September […]
[…] 2019 mushroom blogpost has proven evergreen, an helpful link to drop as introduction ; and it was cited in the Pixelvetica […]
[…] WikiProject Video games. If you are not familiar with that endeavor, I will refer you to the mushroom-rambling blog-post I wrote in September […]